



INTERNATIONAL PRESSOFFICE IN PIXELS
Presspool Roberto Landini
We are a press office and multi-platform media company based in Legnano, Milan, Italy, with a reputation abroad. [See Special Mention]
Since 1993 for international magazines and online since 2000, we have been producing multiplatform contents for tens of international companies, also white label for successful brands -only- in AV areas.
Multi Platform Content
Contenuti Multipiattaforma
Trending Latest










Broadcast RadioTV
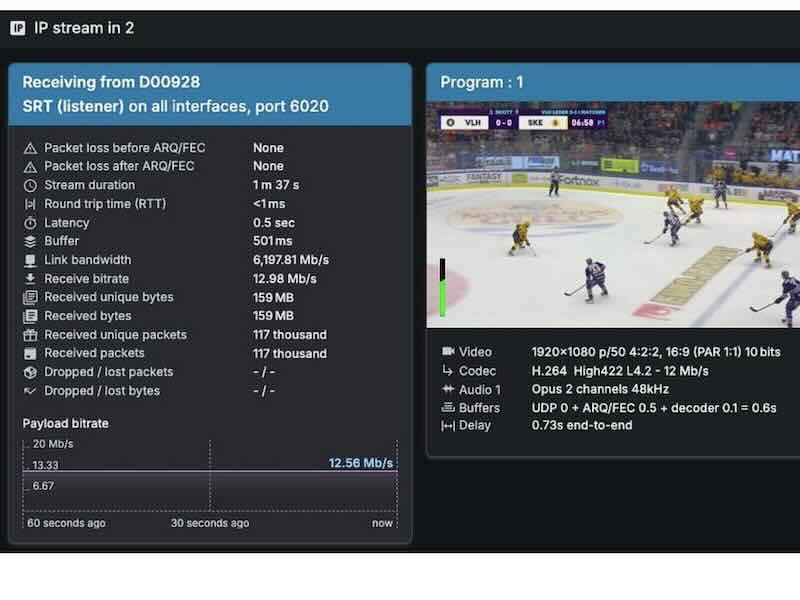



Produzione & Remote Operations







Audio Pro








Sport & News Broadcast






World News




Video Pro






Post & Graphics






Tecnologie Innovative






Associazioni Fiere Educational






BUSINESSES AND TV COMPANIES
Trasforma il tuo sito web in un hub, investi sul ROR, Return On Relation
Presspool Ufficio Stampa in pixel, ti aiuta in ciò che ti distingue
CREA CONTENUTI SU MISURA E LI OTTIMIZZA PER I MOTORI DI RICERCA LI PUBBLICA SUL TUO SITO WEB LI CONDIVIDE SUI SOCIAL MEDIA LI DISTRIBUISCE AI TUOI GRUPPI DI UTENTI
SPESSO OGGI I PRODOTTI SI EQUIVALGONO
Ditelo a noi: noi lo diremo a tutti gli altri
Il Content Marketing parla di storie che rispecchiano le caratteristiche uniche che non tutti hanno e che i vostri clienti sapranno apprezzare.
Noi di Presspool siamo in grado di sottolineare quelle unicità che sono alla base della
vostra personalità aziendale.
Qualosa, un certo "quid", il vostro stile, che si riflette nei vostri prodotti e servizi.
LA DIFFERENZA È FATTA DI PERSONE, OSSIA ...VOI
Raccontiamo ogni volta la vostra "nuova avventura"
Fare risaltare quello che vi contraddistingue non è un compito facile.
Ma è quello che sappiamo fare, con discrezione: quel "continuum" che si percepisce per chi lo sa vedere.
Forse l'innovazione è troppo tecnica e dobbiamo far capire come questa si traduca in un vantaggio reale per i clienti.
Noi cerchiamo, con passione, proprio come voi, di rendere avvincente la vostra storia,
senza mai strafare.
VI AIUTIAMO A SPIEGARE PERCHE' SIETE DIVERSI DAI COMPETITOR
Aumentiamo il Valore Percepito del Vostro Prodotto - Servizio nelle aree:
Acquisizione, Produzione, Distribuzione
ACQUISIZIONE-Contribuzione, Associazioni-Fiere-Educational, Audio Pro, Broadcast
PRODUZIONE, Lighting, Projection, Virtual AR, VR, XR, MR, NewMedia, Post&Graphics
DISTRIBUZIONE, Sport Broadcast, Tecnologie Innovative, Video Pro, Web-Reti, AF-OTT-IP, World News, Radio, Satellite

ACQUISIZIONE
Il primo step nella produzione televisiva e audiovisiva in genere è costituito dalla fase di Acquisizione; quindi qui raccogliamo articoli che riguardano telecamere e sistemi di acquisizione immagini e dell'audio in genere, compresi supporti particolari e camere speciali

PRODUZIONE
L'area della Produzione raccoglie articoli che raccontanto tutto quello che avviene nella complessa fase dopo l'acquisizione. E' qui che un contenuto audiovisivo prende la sua forma definitiva, viene editato, montato, graficato, arricchito e, dopo la post-produzione, diventa un "master".

DISTRIBUZIONE
La Distribuzione permette di collegare i contenuti - finiti e lavorati in produzione e post-produzione - agli utenti finali. Conivolge Delivery, Broadcast, Narrowcast, Reti in genere, Web, Streaming, OTT, canali misti di Monetizzazione Multipiattaforma e Multi Device
Seminari, Workshop, Eventi, Webinar, Fiere...
Appuntamenti da non perdere




















ULTIMISSIME, LATEST NEWS
Le 20 Notizie Più Recenti di Tutte le Categorie
- 2026
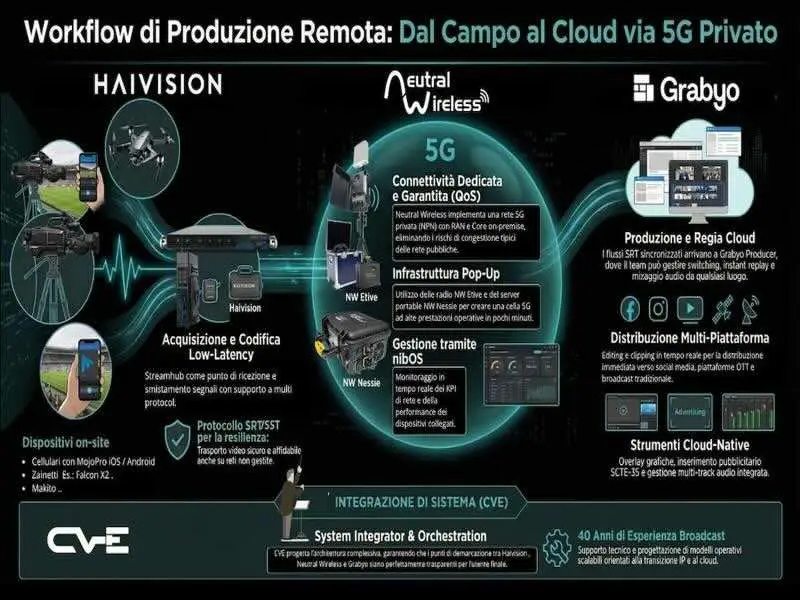
- CVE, Communication Video Engineering, e partner al FED 2026 15:05:26
- Digital Azul e la nuova Master Control Room per produzione remota 14:05:26
- TAG Video Systems Lens riceve tre premi di settore ... 13:05:26
- Intinor presenta al NAB Show 2026 una serie di aggiornamenti per la piattaforma Direkt 12:05:26
- Caretta Research e Zixi: crescono IP e Cloud; riduce il satellite (white paper) 11:05:26
- WorldCast Systems, sicurezza delle reti broadcast, nuova offerta di monitoraggio Kybio 10:05:26
- La tedesca ARD estende l’accordo di distribuzione satellitare con SES per un altro decennio 09:05:26
- Imagine Communications Speciale NAB 26: soluzioni orientate all’innovazione across il portfolio Make and Monetize 08:05:26
- EasyTools entra nella SRT Alliance per il trasporto video IP a bassa latenza 07:05:26
- Interra Systems a BroadcastAsia 2026, soluzioni per il controllo qualità automatizzato, workflow OTT, lineari, etc 06:05:26
- KRK Systems e i monitor Kreate 5 all’interno dei workflow di 555 Studios, Inc., Miami 05:05:26
- Vislink Technologies Speciale NAB 26: insieme integrato di soluzioni RF, 5G private e workflow modulari per la produzione live 04:05:26
- Matrox recap, speciale NAB 2026 03:05:26
- PlayBox Neo Suite e la Media Gateway, soluzione per distribuzione e delivery di contenuti live 02:05:26
- Matthews nuovo Grip Rail con Telescoping Baby Rail 5/8" 01:05:26
- Tradefair a BroadcastAsia 2026, con il padiglione UK 30:04:26
- Telos Alliance partecipa al Media Production & Technology Show 2026 29:04:26
- Small Pixels e MulticoreWare annunciano una partnership strategica... 28:04:26
- LiveU presenta la Q Era a MPTS 2026 con la nuova unità di produzione LU900Q. 27:04:26
- Ocean Blue Software annuncia il lancio di DVB-I Inspector 26:04:26

Linked-in & Soci[al]
Da quest'area potete accedere alle nostre pagine sui maggiori social.
Possiamo curare per voi l'inserimento diretto - nelle vostre aree web news e nelle pagine social - dei contrenuti che vi creiamo.
Sappiamo quali siano gli elementi veri e unici di ogni vostra storia: contenuti indispensabili per ciò che state cercando di trasmettere.
Se state cercando un narratore che si prenda cura di tutto, in modo proattivo, dal contatto, alla stesura, pubblicazione, alla diffusione... noi ci siamo.
La nostra pagina su Linked-in